接上一个项目,在上一个项目的基础上我们来实现熔断器;
一:配置文件
application.properties添加以下内容
feign.hystrix.enabled=true
二:修改consume 项目在 @FeignClient 注释内 添加 fallback属性指定回调类,也就是指定容错处理类 HelloRemoteHystrix.class;
/** * @author: Gavin * Description: 在HelloRemote类添加指定fallback类,在服务熔断的时候返回fallback类中的内容, 定义容错的处理类,当调用远程接口失败或超时时,会调用对应接口的容错逻辑,fallback指定的类必须实现@FeignClient标记的接口 * Date: 2019/1/16 Time: 12:45 * Zhan Hong Copyright (c) 2018 All Rights Reserved. **/@FeignClient(name= "spring-cloud-producer" ,fallback = HelloRemoteHystrix.class)public interface HelloRemote { @RequestMapping(value = "/hello") String hello(@RequestParam(value = "name") String name);} 三 : HelloRemoteHystrix 容错类 来实现 HelloRemote 远程调用接口
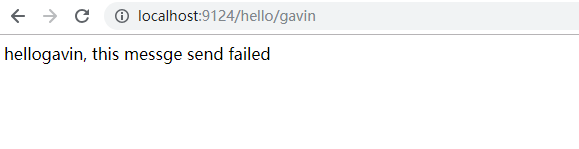
/** * @author: Gavin * Description: HelloRemoteHystrix类继承与HelloRemote实现回调的方法 * Date: 2019/1/17 Time: 10:55 * Zhan Hong Copyright (c) 2018 All Rights Reserved. **/@Componentpublic class HelloRemoteHystrix implements HelloRemote { @Override public String hello(@RequestParam(value = "name") String name) { return "hello" +name+", this messge send failed "; }} 什么是 Hystrix?
在一个分布式系统里,许多依赖不可避免的会调用失败,比如超时、异常等,如何能够保证在一个依赖出问题的情况下,不会导致整体服务失败,这个就是Hystrix需要做的事情。Hystrix提供了熔断、隔离、Fallback、cache、监控等功能,能够在一个、或多个依赖同时出现问题时保证系统依然可用。
所谓的熔断机制和日常生活中见到电路保险丝是非常相似的,当出现了问题之后,保险丝会自动烧断,以保护我们的电器, 在我们的程序中当现在服务的提供方出现了问题之后整个的程序将出现错误的信息显示,而这个时候如果不想出现这样的错误信息,而希望替换为一个错误时的内容。这就是Hystrix 帮我们能做的事情。
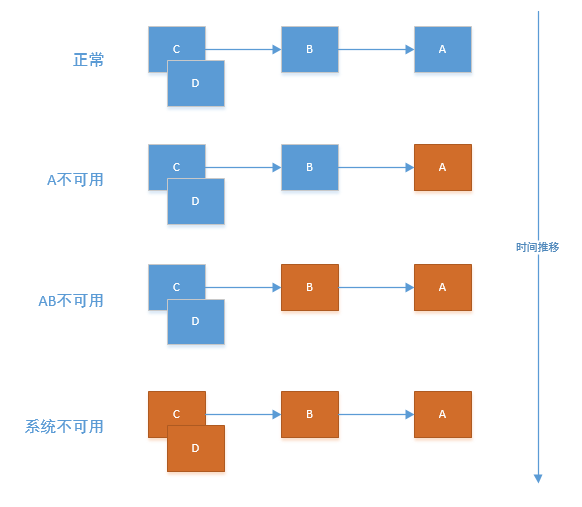
如果下图所示:A作为服务提供者,B为A的服务消费者,C和D是B的服务消费者。A不可用引起了B的不可用,并将不可用像滚雪球一样放大到C和D时,雪崩效应就形成了
Hystrix的设计原则是什么?
- 资源隔离(线程池隔离和信号量隔离)机制:限制调用分布式服务的资源使用,某一个调用的服务出现问题不会影响其它服务调用。
- 限流机制:限流机制主要是提前对各个类型的请求设置最高的QPS阈值,若高于设置的阈值则对该请求直接返回,不再调用后续资源。
- 熔断机制:当失败率达到阀值自动触发降级(如因网络故障、超时造成的失败率真高),熔断器触发的快速失败会进行快速恢复。
- 降级机制:超时降级、资源不足时(线程或信号量)降级 、运行异常降级等,降级后可以配合降级接口返回托底数据。
- 缓存支持:提供了请求缓存、请求合并实现
- 通过近实时的统计/监控/报警功能,来提高故障发现的速度
- 通过近实时的属性和配置热修改功能,来提高故障处理和恢复的速度
分别启动 eureka,producer, consume 三个项目
访问服务提供者 producer , 在浏览器输入 http://localhost:9167/hello?name=gavin

访问服务提供者 consume, 在浏览器输入 http://localhost:9124/hello/gavin

服务提供者和消费者项目都可访问;我们手动停止producer 项目,在访问consume 测试熔断器;